publications
peer-reviewed publications in reversed chronological order
2026
-
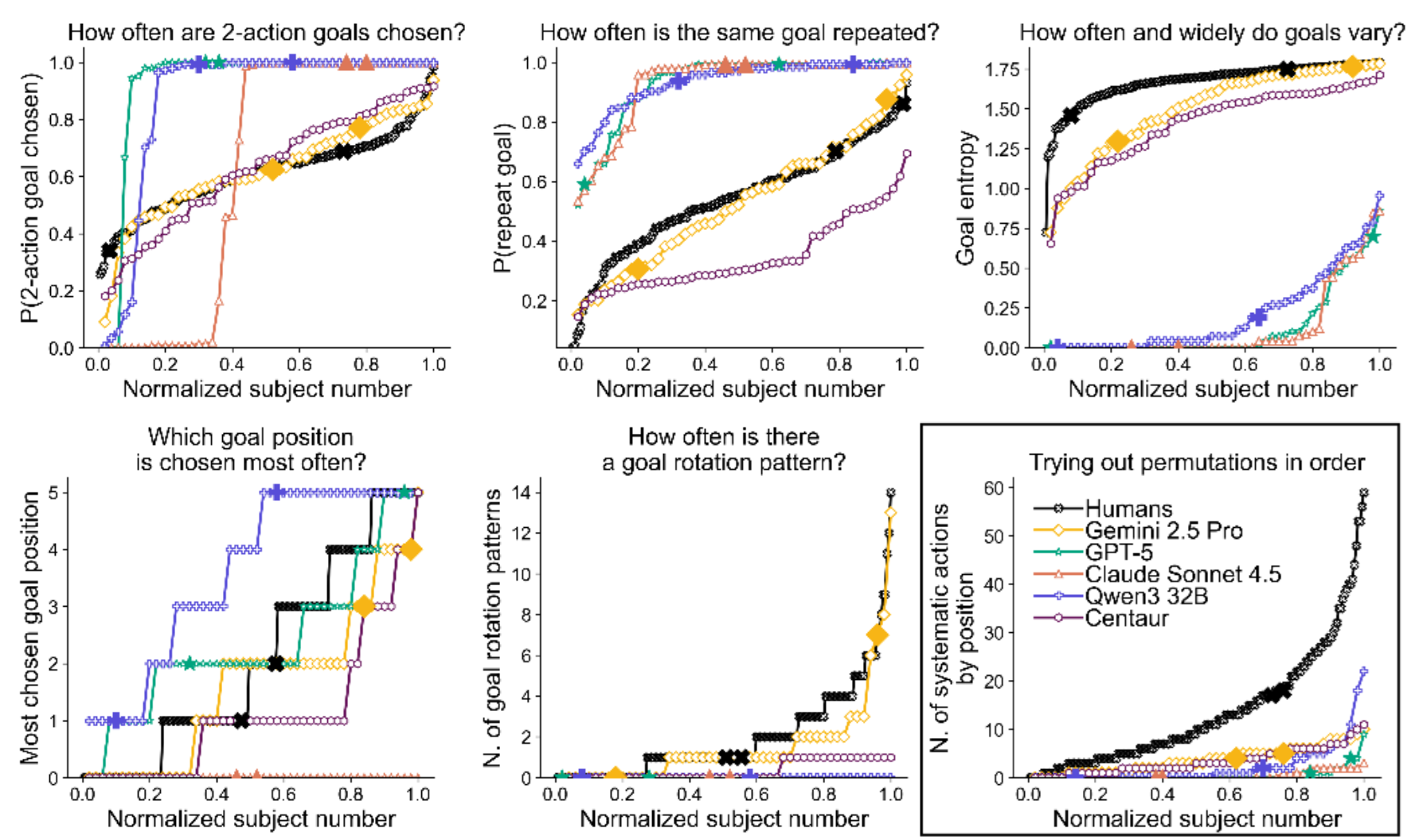 Language model goal selection differs from humans’ in a self-driven learning taskGaia Molinaro, Dave August, Danielle Perszyk, and 1 more authorarXiv preprint arXiv:2603.03295v2, 2026
Language model goal selection differs from humans’ in a self-driven learning taskGaia Molinaro, Dave August, Danielle Perszyk, and 1 more authorarXiv preprint arXiv:2603.03295v2, 2026Whether in agentic workflows, social studies, or chat settings, large language models (LLMs) are increasingly being asked to replace humans in choosing which goals to pursue, rather than completing predefined tasks. However, the assumption that LLMs accurately reflect human preferences for goal setting remains largely untested. We assess the validity of LLMs as proxies for human goal selection in a controlled, self-directed learning task borrowed from cognitive science. Across five models (GPT-5, Gemini 2.5 Pro, Claude Sonnet 4.5, Qwen3 32B, and Centaur), we find substantial divergence from human behavior. While people gradually explore and learn to achieve goals with diversity across individuals, most models exploit a single identified solution or show surprisingly low performance, with distinct patterns across models and little variability across instances of the same model. Chain-of-thought reasoning and persona steering provide limited improvements, and our conclusions hold across experimental settings. While they await confirmation in applied settings, these findings highlight the uniqueness of human goal selection and caution against its replacement with current models.
@article{molinaro2026language, title = {Language model goal selection differs from humans' in a self-driven learning task}, author = {Molinaro, Gaia and August, Dave and Perszyk, Danielle and Collins, Anne GE}, journal = {arXiv preprint arXiv:2603.03295v2}, year = {2026}, } -
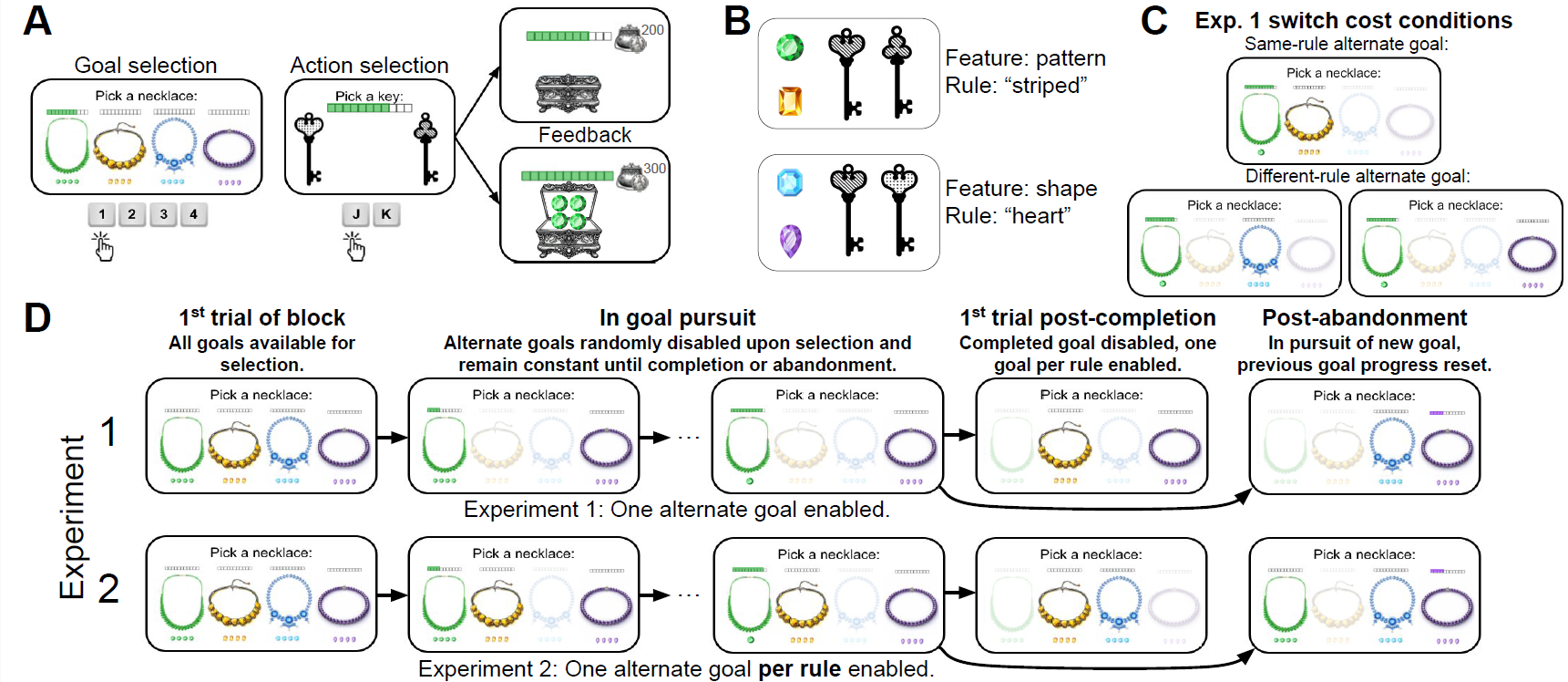 Investigating the role of task representation switch costs in goal persistenceGaia Molinaro, Aly Lidayan, and Anne GE CollinsIn CogSci, 2026
Investigating the role of task representation switch costs in goal persistenceGaia Molinaro, Aly Lidayan, and Anne GE CollinsIn CogSci, 2026Goal pursuit profoundly shapes human cognition. This is often beneficial – for example, by focusing information processing. However, goal-dependent computations occasionally lead to seemingly maladaptive behavior, such as a bias toward goal persistence – the tendency to continue pursuing the current goal even when suboptimal. While various psychological explanations have been proposed for goal persistence, the underlying cognitive mechanisms remain unclear. Here, we explore one potential hypothesis. We posit that switching goals incurs the computational cost of reconfiguring internal representations, e.g., to new stimulus-action mappings, and that this cost motivates persisting in a goal even when another is more valuable. Thus, we predict that 1) higher reconfiguration costs will increase persistence bias, and 2) given the choice, participants will prefer switching to lower-cost goals. To test these predictions, we developed a task where participants chose between competing goals, and sudden changes in the task dynamics encouraged goal abandonment toward more valuable options. Crucially, some goals shared the same action selection rule, while others required different rules, allowing us to test how similar vs. different internal representations influenced goal persistence. Across two experiments (N = 125), we replicated goal persistence biases and found that stimulus-action representation switch costs influence both goal persistence and selection preferences. However, they only accounted for a small part of the total goal persistence, suggesting that such biases are predominantly driven by other factors.
@inproceedings{molinaro2026investigating, title = {Investigating the role of task representation switch costs in goal persistence}, author = {Molinaro, Gaia and Lidayan, Aly and Collins, Anne GE}, booktitle = {CogSci}, volume = {48}, year = {2026}, } -
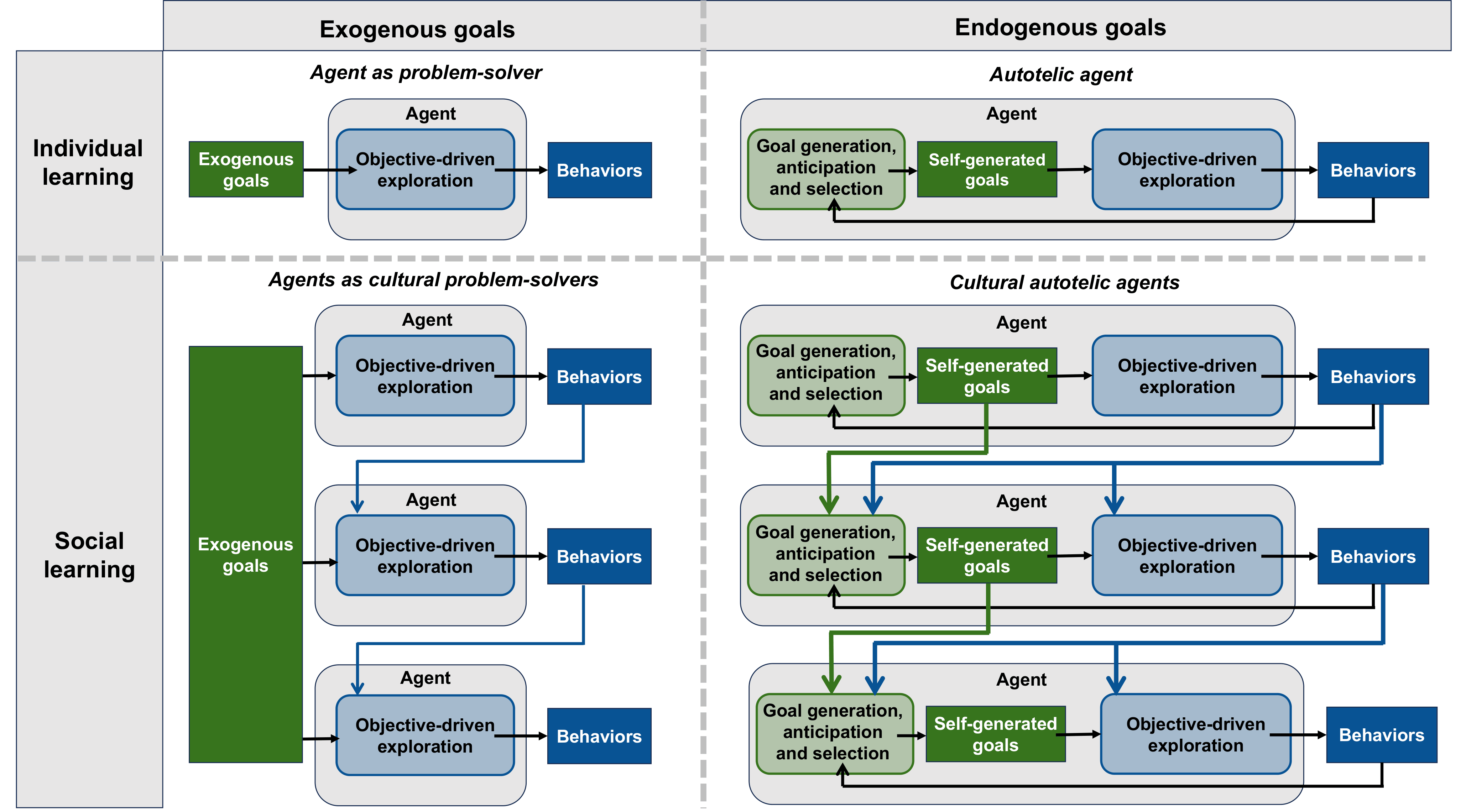 The cultural evolution of human goalsJéréremy Perez, Cédric Colas, Gaia Molinaro, and 3 more authorsPsyArXiv, 2026
The cultural evolution of human goalsJéréremy Perez, Cédric Colas, Gaia Molinaro, and 3 more authorsPsyArXiv, 2026Humans pursue remarkably diverse goals that vary over time and across cultures. These goals are both drivers and products of cultural evolutionary dynamics, yet most theories of cultural evolution have focused on the influence of culture on how individuals reach their goals, rather than on which goals they pursue. We argue that understanding the cultural dynamics of goals requires grounding them in the cognitive mechanisms through which individuals generate, evaluate, and select them. To this end, we draw on research on intrinsic motivation and curiosity in cognitive science and artificial intelligence to introduce the concept of cultural autotelic agents: individuals whose goal generation, anticipation, and selection mechanisms are shaped by, and in turn shape, their cultural environment. This framework reveals the key but underappreciated role of intrinsic motivation in promoting the diversity of goals and behaviors in ways that help sustain the open-ended nature of human culture.
@article{perez2026cultural, title = {The cultural evolution of human goals}, publisher = {OSF}, journal = {PsyArXiv}, year = {2026}, author = {Perez, Jéréremy and Colas, Cédric and Molinaro, Gaia and Oudeyer, Pierre-Yves and Derex, Maxime and Moulin-Frier, Clément}, } -
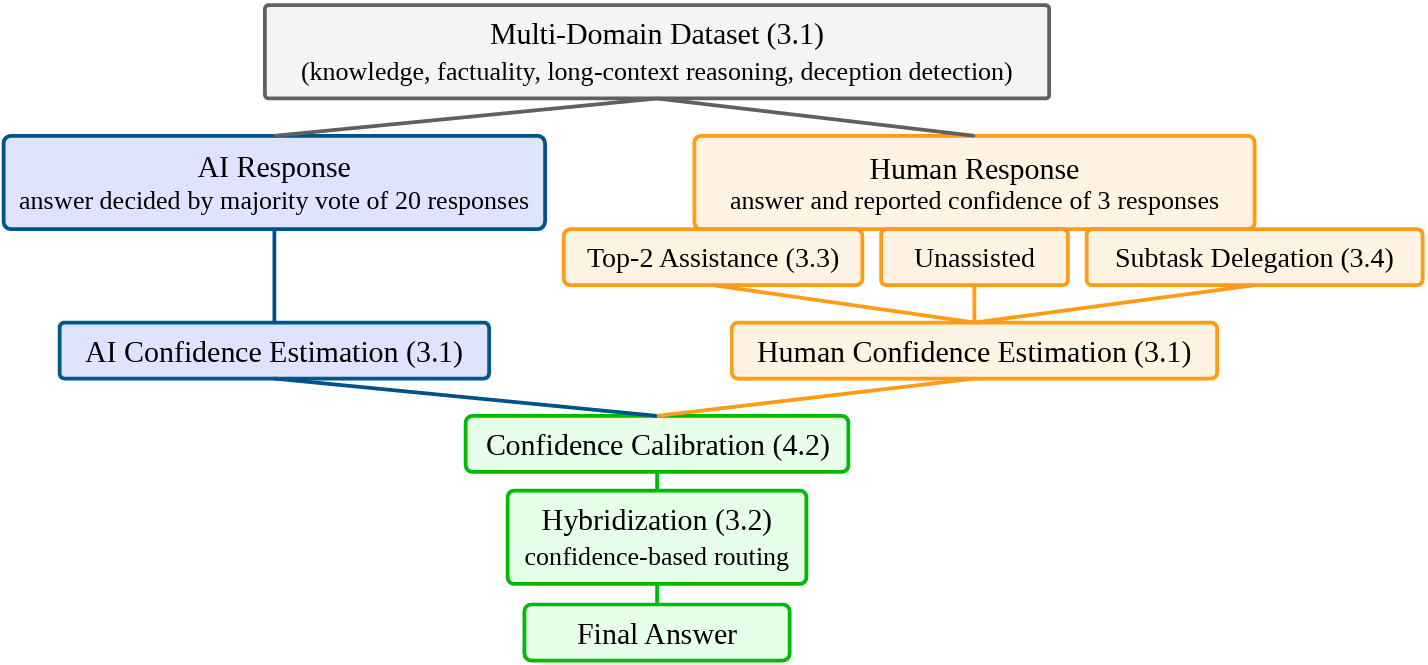 Toward human-AI complementarity across diverse tasksYuzheng Xu, Annya Dahmani, Matthew D Blanchard, and 8 more authorsarXiv preprint arXiv:2605.04070, 2026
Toward human-AI complementarity across diverse tasksYuzheng Xu, Annya Dahmani, Matthew D Blanchard, and 8 more authorsarXiv preprint arXiv:2605.04070, 2026Human-AI complementarity, the idea that combining human and AI judgments can outperform either alone, offers a promising pathway toward robust oversight of advanced AI systems. However, whether human-AI complementarity can be achieved on realistic tasks remains an open question. We investigate this through two approaches: hybridization and two AI assistance methods (top-2 assistance and subtask delegation), evaluated on a multi-domain dataset of 1,886 samples spanning knowledge, factuality, long-context reasoning, and deception detection. We find only modest complementarity gains. Baseline hybridization yields just +0.4 percentage points (pp) over AI alone (69.3% vs 68.9%), limited both by a small complementarity region (only 8.9% of items where AI errs but humans do not) and the inability of confidence-based routing to identify it, since the model’s confidence is similarly distributed across correct and incorrect predictions. Applied when AI has low confidence, top-2 assistance increases human accuracy from 28.4% to 38.3%, surpassing AI alone (37.7%) – but primarily because humans adopt correct AI suggestions, not because they successfully override AI errors. These findings suggest that the primary bottleneck is not human task accuracy per se, but the ability to route decisions to humans when it matters and to design assistance methods that enable humans to catch AI mistakes. Our quantitative and qualitative analyses pinpoint where and why each method succeeds or fails, offering concrete targets for future work. We will release our dataset and code upon request to support progress toward more effective human-AI collaboration for AI oversight.
@article{xu2026toward, title = {Toward human-AI complementarity across diverse tasks}, author = {Xu, Yuzheng and Dahmani, Annya and Blanchard, Matthew D and Dern, Niclas and Nastase, Edy and Bianco, Francesca and Pavlovic, Maja and Krishna, Sukanya and Modesitt, Eric and Christ, Miranda Anna and others}, journal = {arXiv preprint arXiv:2605.04070}, year = {2026}, }
2025
-
 When LLMs play the telephone game: Cumulative changes and attractors in iterated cultural transmissionsJérémy Perez, Grgur Kovač, Corentin Léger, and 5 more authorsICLR, 2025
When LLMs play the telephone game: Cumulative changes and attractors in iterated cultural transmissionsJérémy Perez, Grgur Kovač, Corentin Léger, and 5 more authorsICLR, 2025As large language models (LLMs) start interacting with each other and generating an increasing amount of text online, it becomes crucial to better understand how information is transformed as it passes from one LLM to the next. While significant research has examined individual LLM behaviors, existing studies have largely overlooked the collective behaviors and information distortions arising from iterated LLM interactions. Small biases, negligible at the single output level, risk being amplified in iterated interactions, potentially leading the content to evolve towards attractor states. In a series of telephone game experiments, we apply a transmission chain design borrowed from the human cultural evolution literature: LLM agents iteratively receive, produce, and transmit texts from the previous to the next agent in the chain. By tracking the evolution of text toxicity, positivity, difficulty, and length across transmission chains, we uncover the existence of biases and attractors, and study their dependence on the initial text, the instructions, language model, and model size. For instance, we find that more open-ended instructions lead to stronger attraction effects compared to more constrained tasks. We also find that different text properties display different sensitivity to attraction effects, with toxicity leading to stronger attractors than length. These findings highlight the importance of accounting for multi-step transmission dynamics and represent a first step towards a more comprehensive understanding of LLM cultural dynamics.
@article{perez2024llms, title = {When LLMs play the telephone game: Cumulative changes and attractors in iterated cultural transmissions}, author = {Perez, J{\'e}r{\'e}my and Kova{\v{c}}, Grgur and L{\'e}ger, Corentin and Colas, C{\'e}dric and Molinaro, Gaia and Derex, Maxime and Oudeyer, Pierre-Yves and Moulin-Frier, Cl{\'e}ment}, journal = {ICLR}, year = {2025}, } -
 Spontaneous thought as play: the value of fictional goals in the default mode networkGaia Molinaro and Moshe BarCurrent Opinion in Behavioral Sciences, 2025
Spontaneous thought as play: the value of fictional goals in the default mode networkGaia Molinaro and Moshe BarCurrent Opinion in Behavioral Sciences, 2025Given its prevalence in our wakeful mental activity, spontaneous thought (ST) has been attributed several roles in cognition, most of which engage the brain’s default mode network. Among the benefits of ST is its ability to support the proactive simulation of possible future scenarios, including situations that, prima facie, may seem frivolous, futile, or simply unlikely. By drawing an analogy between ST and children’s play, we propose a substantial role for what might otherwise seem like useless mental activity. In children’s play, ‘fictional’ activities have been argued to hold inherent value, as they hone the capacity to generate new plans and ideas — even if never pursued — and the ability to generate increasingly accurate simulations. We suggest that ST similarly provides a platform for the simulation of goals and scenarios outside the boundaries of what is likely or even feasible in the given context, facilitating learning and innovation. In this capacity, ST supports human intelligence and mental well-being. We discuss the implications of our proposal for the understanding of ST and its underlying neural circuitry.
@article{molinaro2025spontaneous, title = {Spontaneous thought as play: the value of fictional goals in the default mode network}, author = {Molinaro, Gaia and Bar, Moshe}, journal = {Current Opinion in Behavioral Sciences}, volume = {63}, pages = {101504}, year = {2025}, } -
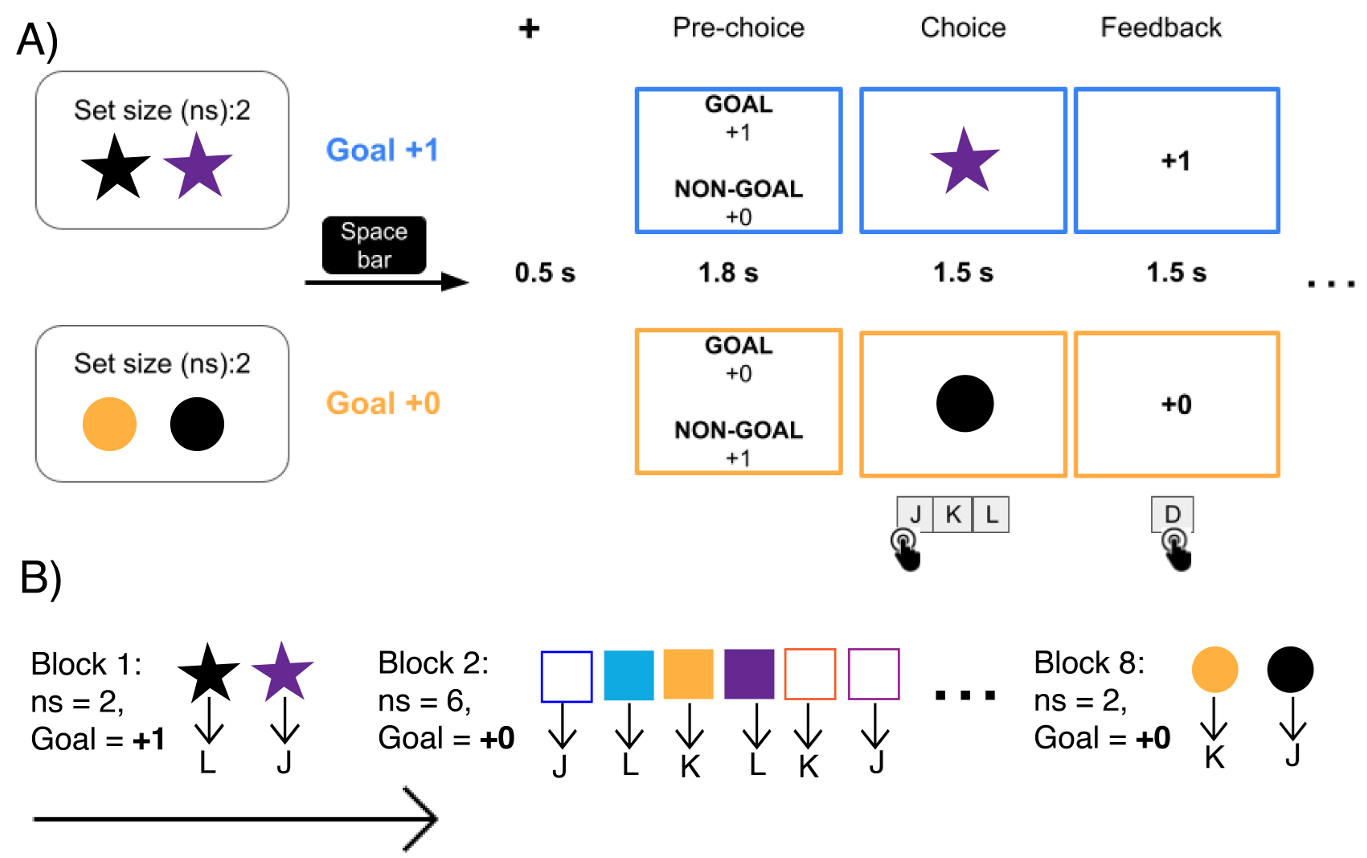 When 0 is good: instrumental learning with counterintuitive goals decreases working memory engagementTi-Fen Pan, Gaia Molinaro, and Anne G. E. CollinsIn CogSci, 2025
When 0 is good: instrumental learning with counterintuitive goals decreases working memory engagementTi-Fen Pan, Gaia Molinaro, and Anne G. E. CollinsIn CogSci, 2025Humans are adept at setting goals quickly and flexibly in their daily lives. Previous research has shown that people can assign rewarding properties to abstract or novel outcomes and use them to guide behavior. However, the mechanisms supporting this flexibility and their impact on learning processes, such as working memory (WM) or slower incremental systems, remain unclear. To address this, we designed an instrumental learning task in which participants learned stimulus-action associations by pursuing either standard goals (+1) or counterintuitive goals (+0) under varying WM loads. Our behavioral and modeling results revealed that when pursuing counterintuitive goals, humans learned more slowly and shifted their reliance from WM to habit-like associative processes, despite both processes remaining functionally intact. Additionally, we replicated previous findings showing that humans do not rely on reinforcement learning (RL) processes but instead integrate WM and habit-like processes to learn the associations. This interplay between WM and habit-like processes may allow a more resource-efficient approach to pursuing diverse goals. Our findings shed light on the breadth and cost of people’s ability to flexibly learn and pursue any goal.
@inproceedings{pan20250, title = {When 0 is good: instrumental learning with counterintuitive goals decreases working memory engagement}, author = {Pan, Ti-Fen and Molinaro, Gaia and Collins, Anne G. E.}, booktitle = {CogSci}, volume = {47}, year = {2025}, } -
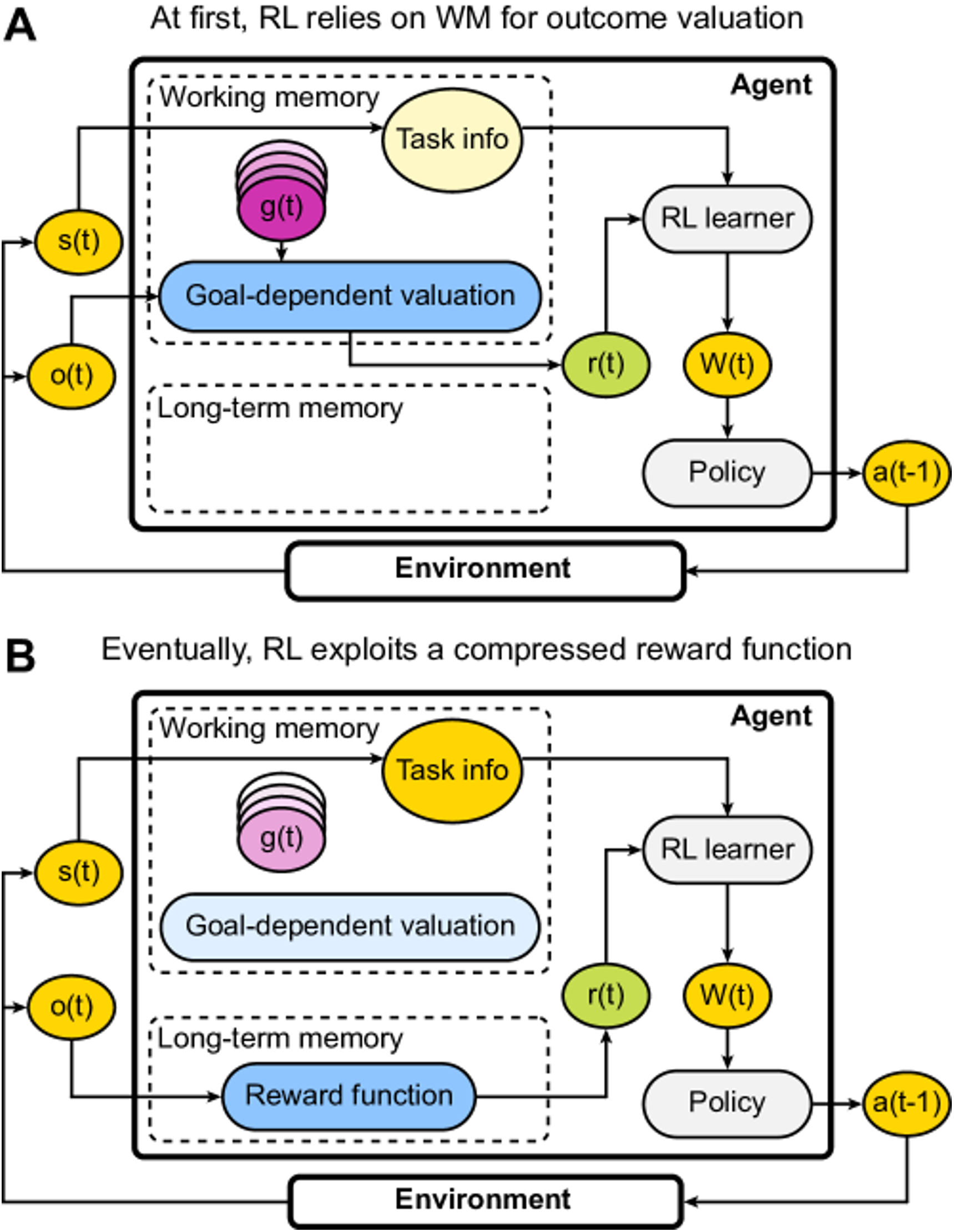 Reward function compression facilitates goal-dependent reinforcement learningGaia Molinaro and Anne GE CollinsarXiv preprint arXiv:2509.06810v2, 2025
Reward function compression facilitates goal-dependent reinforcement learningGaia Molinaro and Anne GE CollinsarXiv preprint arXiv:2509.06810v2, 2025Reinforcement learning agents learn from rewards, but humans can uniquely assign value to novel, abstract outcomes in a goal-dependent manner. However, this flexibility is cognitively costly, making learning less efficient. Here, we propose that goal-dependent learning is initially supported by a capacity-limited working memory system. With consistent experience, learners create a "compressed" reward function (a simplified rule defining the goal) which is then transferred to long-term memory and applied automatically upon receiving feedback. This process frees up working memory resources, boosting learning efficiency. We test this theory across six experiments. Consistent with our predictions, our findings demonstrate that learning is parametrically impaired by the size of the goal space, but improves when the goal space structure allows for compression. We also find faster reward processing to correlate with better learning performance, supporting the idea that as goal valuation becomes more automatic, more resources are available for learning. We leverage computational modeling to support this interpretation. Our work suggests that efficient goal-directed learning relies on compressing complex goal information into a stable reward function, shedding light on the cognitive mechanisms of human motivation. These findings generate new insights into the neuroscience of intrinsic motivation and could help improve behavioral techniques that support people in achieving their goals.
@article{molinaro2025reward, title = {Reward function compression facilitates goal-dependent reinforcement learning}, author = {Molinaro, Gaia and Collins, Anne GE}, journal = {arXiv preprint arXiv:2509.06810v2}, year = {2025}, }
2024
-
 What should I do now? Goal-centric outlooks on learning, exploration, and communicationCédric Colas, Junyi Chu, Gaia Molinaro, and 1 more authorIn CogSci, 2024
What should I do now? Goal-centric outlooks on learning, exploration, and communicationCédric Colas, Junyi Chu, Gaia Molinaro, and 1 more authorIn CogSci, 2024Goals are a central pillar of everyday mental activity. From finding your way home to solving a puzzle and ordering food delivery, much of human action and cognition is goal-directed. Perhaps unsurprisingly, theories of goals are a central focus in the psychology of motivation (Elliott & Dweck, 1988), in social and personality psychology (Fishbach & Ferguson, 2007), as well as research aimed at understanding factors contributing to task achievement in educational and industrial settings (Ames & Ames, 1984; Locke & Latham, 2002). In this symposium, we highlight recent work emphasizing a goal-centric outlook on learning, exploration, and communication.
@inproceedings{colas2024should, title = {What should I do now? Goal-centric outlooks on learning, exploration, and communication}, author = {Colas, C{\'e}dric and Chu, Junyi and Molinaro, Gaia and Hawkins, Robert}, booktitle = {CogSci}, volume = {46}, year = {2024}, } -
 Latent learning progress drives autonomous goal selection in human reinforcement learningGaia Molinaro, Cédric Colas, Pierre-Yves Oudeyer, and 1 more authorNeurIPS, 2024
Latent learning progress drives autonomous goal selection in human reinforcement learningGaia Molinaro, Cédric Colas, Pierre-Yves Oudeyer, and 1 more authorNeurIPS, 2024Humans are autotelic agents who learn by setting and pursuing their own goals. However, the precise mechanisms guiding human goal selection remain unclear. Learning progress, typically measured as the observed change in performance, can provide a valuable signal for goal selection in both humans and artificial agents. We hypothesize that human choices of goals may also be driven by latent learning progress, which humans can estimate through knowledge of their actions and the environment – even without experiencing immediate changes in performance. To test this hypothesis, we designed a hierarchical reinforcement learning task in which human participants (N = 175) repeatedly chose their own goals and learned goal-conditioned policies. Our behavioral and computational modeling results confirm the influence of latent learning progress on goal selection and uncover inter-individual differences, partially mediated by recognition of the task’s hierarchical structure. By investigating the role of latent learning progress in human goal selection, we pave the way for more effective and personalized learning experiences as well as the advancement of more human-like autotelic machines.
@article{molinaro2024latent, title = {Latent learning progress drives autonomous goal selection in human reinforcement learning}, author = {Molinaro, Gaia and Colas, C{\'e}dric and Oudeyer, Pierre-Yves and Collins, Anne GE}, journal = {NeurIPS}, volume = {37}, year = {2024}, } -
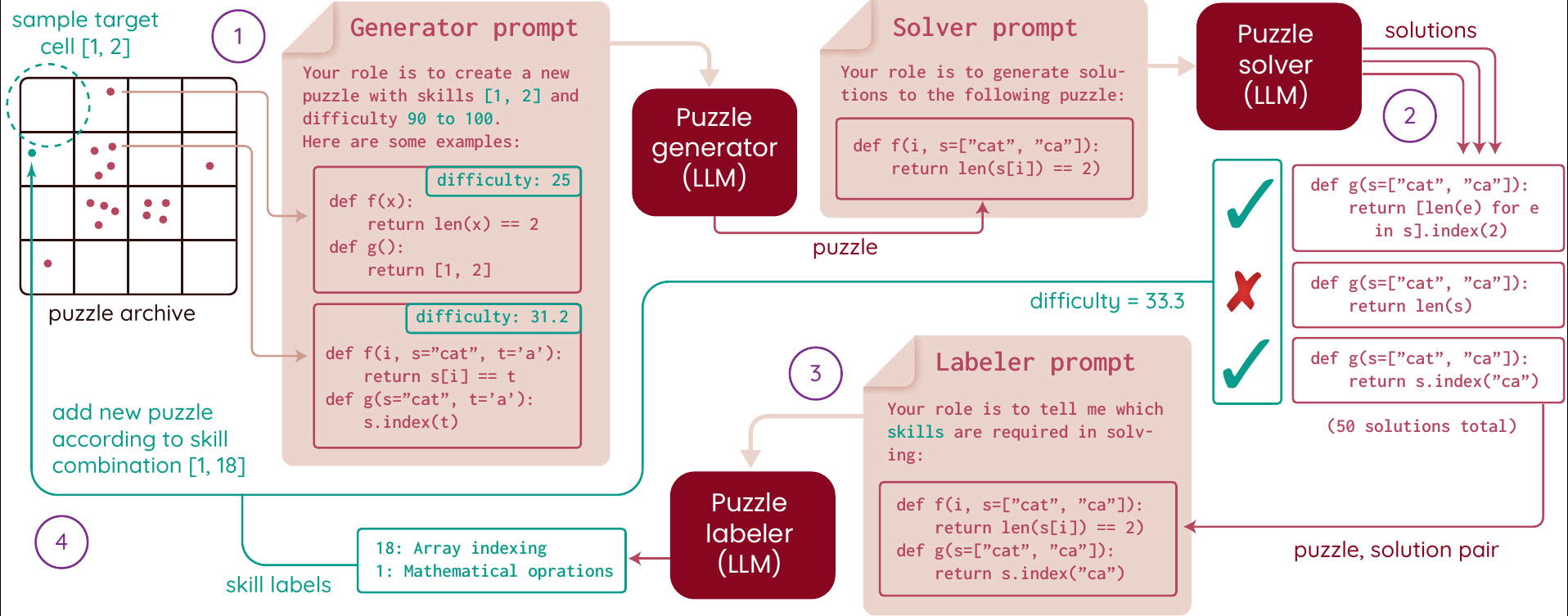 ACES: generating diverse programming puzzles with autotelic language models and semantic descriptorsJulien Pourcel, Cédric Colas, Gaia Molinaro, and 2 more authorsNeurIPS, 2024
ACES: generating diverse programming puzzles with autotelic language models and semantic descriptorsJulien Pourcel, Cédric Colas, Gaia Molinaro, and 2 more authorsNeurIPS, 2024Finding and selecting new and interesting problems to solve is at the heart of curiosity, science and innovation. We here study automated problem generation in the context of the open-ended space of python programming puzzles. Existing generative models often aim at modeling a reference distribution without any explicit diversity optimization. Other methods explicitly optimizing for diversity do so either in limited hand-coded representation spaces or in uninterpretable learned embedding spaces that may not align with human perceptions of interesting variations. With ACES (Autotelic Code Exploration via Semantic descriptors), we introduce a family of autotelic generation methods that leverage semantic descriptors evaluated by a large language model (LLM) to directly optimize for interesting diversity. Each puzzle is labeled along 10 dimensions, each capturing a programming skill required to solve it. ACES generates and pursues novel and feasible goals to explore that abstract semantic space, slowly discovering a diversity of solvable programming puzzles in any given run. Across a set of experiments, we show that ACES discovers a richer diversity of puzzles than existing diversity-maximizing algorithms as measured across a range of diversity metrics. We further study whether and in which conditions this diversity can translate into the successful training of puzzle solving models.
@article{pourcel2024aces, title = {ACES: generating diverse programming puzzles with autotelic language models and semantic descriptors}, author = {Pourcel, Julien and Colas, C{\'e}dric and Molinaro, Gaia and Oudeyer, Pierre-Yves and Teodorescu, Laetitia}, journal = {NeurIPS}, year = {2024}, }
2023
-
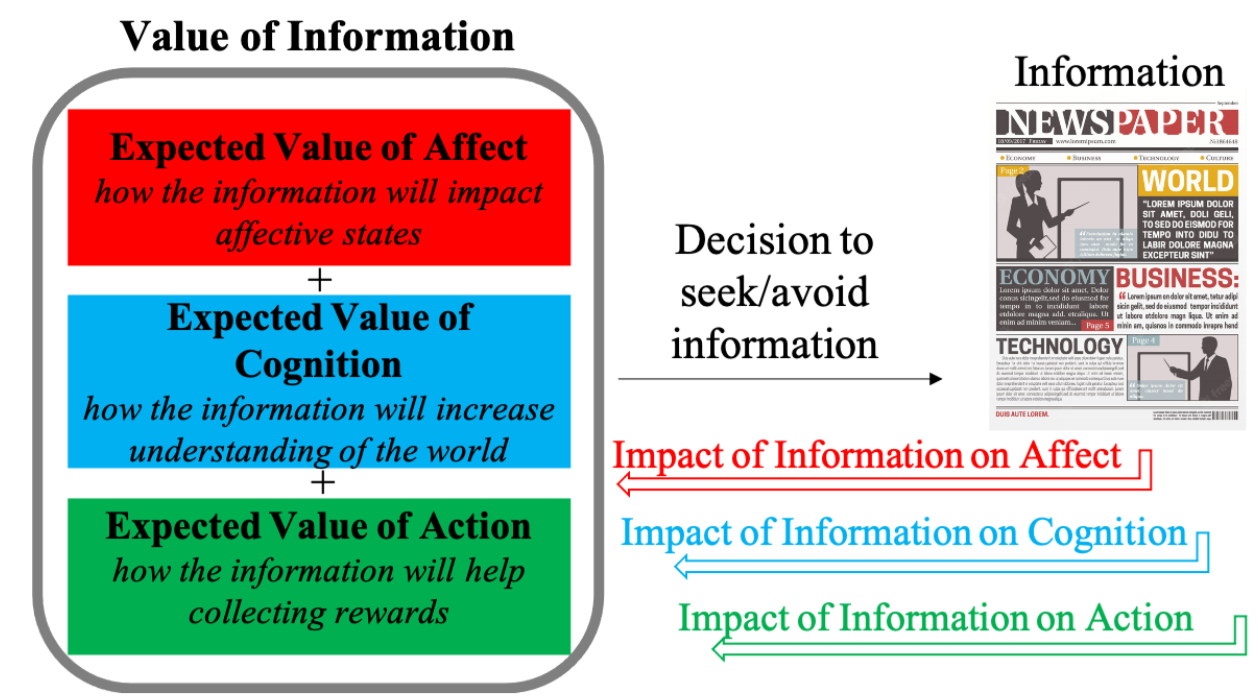 A reinforcement learning framework for information-seeking and information-avoidanceIrene Cogliati Dezza, Gaia Molinaro, and Tom VergutsIn CogSci, 2023
A reinforcement learning framework for information-seeking and information-avoidanceIrene Cogliati Dezza, Gaia Molinaro, and Tom VergutsIn CogSci, 2023Every day, people are exposed to vast amounts of information that can impact how they feel, think about, and act upon the world. Here, we extend the computational reinforcement learning framework to explain how such an impact can shape future decisions to either seek or avoid information. By simulating human behavioral data, we showed that agents are more likely to seek information after exposure to information with a positive net impact on the agent’s affect, cognition, and ability to make good decisions. The more the agent is exposed to this kind of information, the higher the probability that it will seek even more information in the future. On the contrary, decisions to remain ignorant are more likely to occur after repeated exposure to information with a negative net impact. Our model offers a novel computational framework within which maladaptive information-seeking and information-avoidance behaviors can be further investigated.
@inproceedings{cogliatidezza2023reinforcement, title = {A reinforcement learning framework for information-seeking and information-avoidance}, author = {Cogliati Dezza, Irene and Molinaro, Gaia and Verguts, Tom}, booktitle = {CogSci}, volume = {45}, number = {45}, year = {2023}, } -
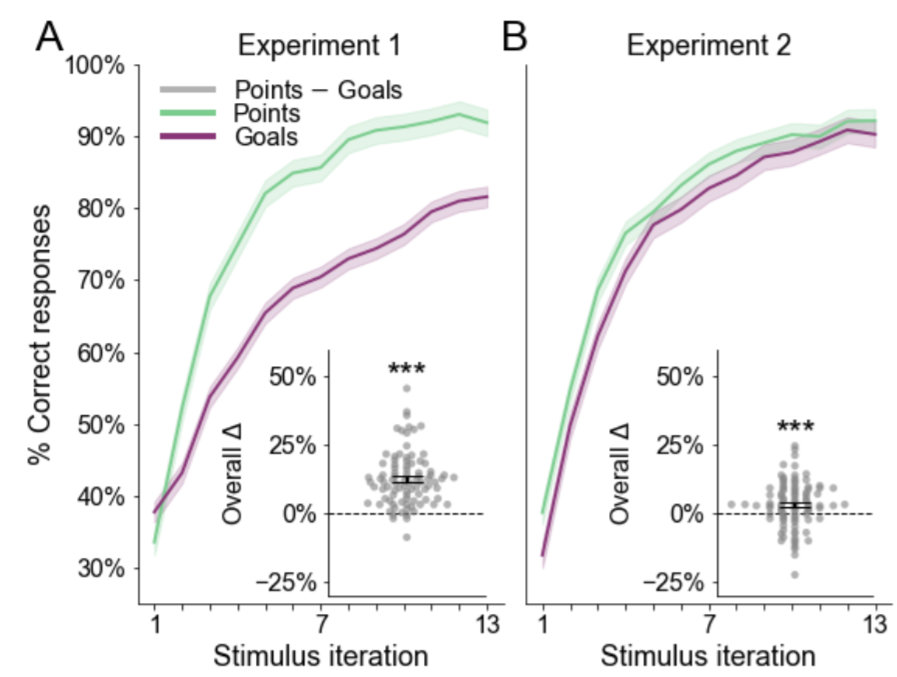 Human hacks and bugs in the recruitment of reward systems for goal achievementGaia Molinaro and Anne GE CollinsIn CogSci, 2023
Human hacks and bugs in the recruitment of reward systems for goal achievementGaia Molinaro and Anne GE CollinsIn CogSci, 2023Human learning is often motivated by self-imposed challenges, which guide behavior even in the absence of external rewards. Previous studies have shown that humans can use personal goals to "hack" the definition of reward, warranting an extension of the classic reinforcement learning framework to account for the flexible attribution of value to outcomes according to current goals. However, learning through goal-derived outcomes is less efficient than learning through more established reinforcers, such as numeric points. At least three possible explanations exist for this sort of impairment, or "bug". First, occasional lapses in executive function, which is required to encode and recognize goals, may result in subsequent failure to update values accordingly. Second, the higher working memory load required to encode novel stimuli as desirable outcomes may impair people’s ability to update and remember correct stimulus-reward associations. Third, a weaker commitment to arbitrary goals may result in dimmer appetitive signals. By extending existing experimental paradigms that include learning from both familiar rewards and abstract, goal-contingent outcomes and combining them with computational modeling techniques, we find evidence for each of the proposed accounts. While other factors might also play a role in this process, our results provide an initial indication of the key elements supporting (or impairing) the attribution of rewarding properties to otherwise neutral stimuli, which enable humans to better pursue arbitrarily set goals.
@inproceedings{molinaro2023human, title = {Human hacks and bugs in the recruitment of reward systems for goal achievement}, author = {Molinaro, Gaia and Collins, Anne GE}, booktitle = {CogSci}, volume = {45}, number = {45}, year = {2023}, } -
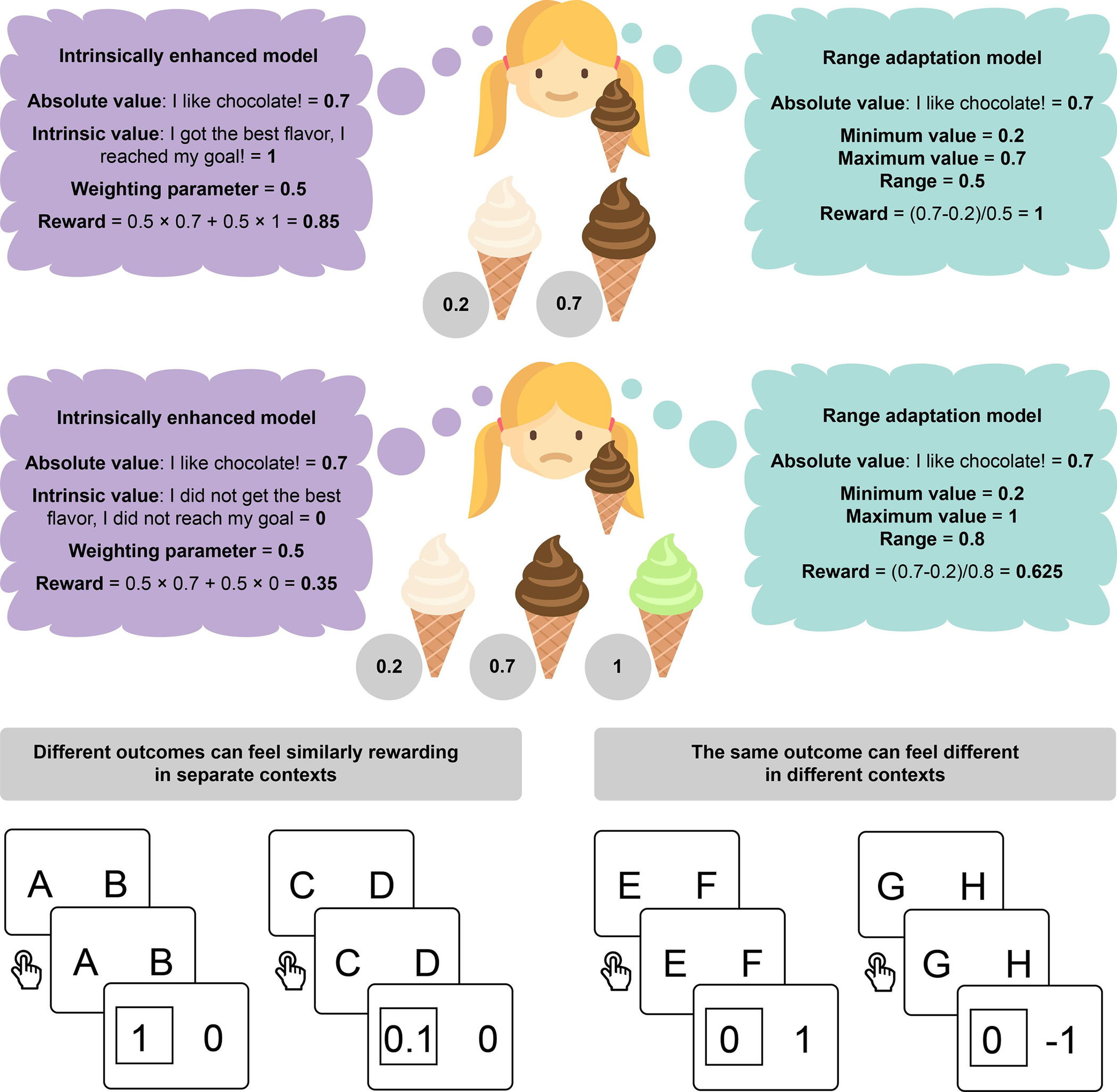 Intrinsic rewards explain context-sensitive valuation in reinforcement learningGaia Molinaro and Anne G. E. CollinsPLOS Biology, 2023
Intrinsic rewards explain context-sensitive valuation in reinforcement learningGaia Molinaro and Anne G. E. CollinsPLOS Biology, 2023When observing the outcome of a choice, people are sensitive to the choice’s context, such that the experienced value of an option depends on the alternatives: getting $1 when the possibilities were 0 or 1 feels much better than when the possibilities were 1 or 10. Context-sensitive valuation has been documented within reinforcement learning (RL) tasks, in which values are learned from experience through trial and error. Range adaptation, wherein options are rescaled according to the range of values yielded by available options, has been proposed to account for this phenomenon. However, we propose that other mechanisms—reflecting a different theoretical viewpoint—may also explain this phenomenon. Specifically, we theorize that internally defined goals play a crucial role in shaping the subjective value attributed to any given option. Motivated by this theory, we develop a new “intrinsically enhanced” RL model, which combines extrinsically provided rewards with internally generated signals of goal achievement as a teaching signal. Across 7 different studies (including previously published data sets as well as a novel, preregistered experiment with replication and control studies), we show that the intrinsically enhanced model can explain context-sensitive valuation as well as, or better than, range adaptation. Our findings indicate a more prominent role of intrinsic, goal-dependent rewards than previously recognized within formal models of human RL. By integrating internally generated signals of reward, standard RL theories should better account for human behavior, including context-sensitive valuation and beyond.
@article{molinaro2023intrinsic, title = {Intrinsic rewards explain context-sensitive valuation in reinforcement learning}, author = {Molinaro, Gaia and Collins, Anne G. E.}, journal = {PLOS Biology}, volume = {21}, number = {7}, pages = {e3002201}, year = {2023}, publisher = {PLOS}, } -
 A goal-centric outlook on learningGaia Molinaro and Anne GE CollinsTrends in Cognitive Sciences, 2023
A goal-centric outlook on learningGaia Molinaro and Anne GE CollinsTrends in Cognitive Sciences, 2023Goals play a central role in human cognition. However, computational theories of learning and decision-making often take goals as given. Here, we review key empirical findings showing that goals shape the representations of inputs, responses, and outcomes, such that setting a goal crucially influences the central aspects of any learning process: states, actions, and rewards. We thus argue that studying goal selection is essential to advance our understanding of learning. By following existing literature in framing goal selection within a hierarchy of decision-making problems, we synthesize important findings on the principles underlying goal value attribution and exploration strategies. Ultimately, we propose that a goal-centric perspective will help develop more complete accounts of learning in both biological and artificial agents.
@article{molinaro2023goal, title = {A goal-centric outlook on learning}, author = {Molinaro, Gaia and Collins, Anne GE}, journal = {Trends in Cognitive Sciences}, volume = {27}, number = {12}, pages = {1150--1164}, year = {2023}, publisher = {Elsevier Current Trends}, } -
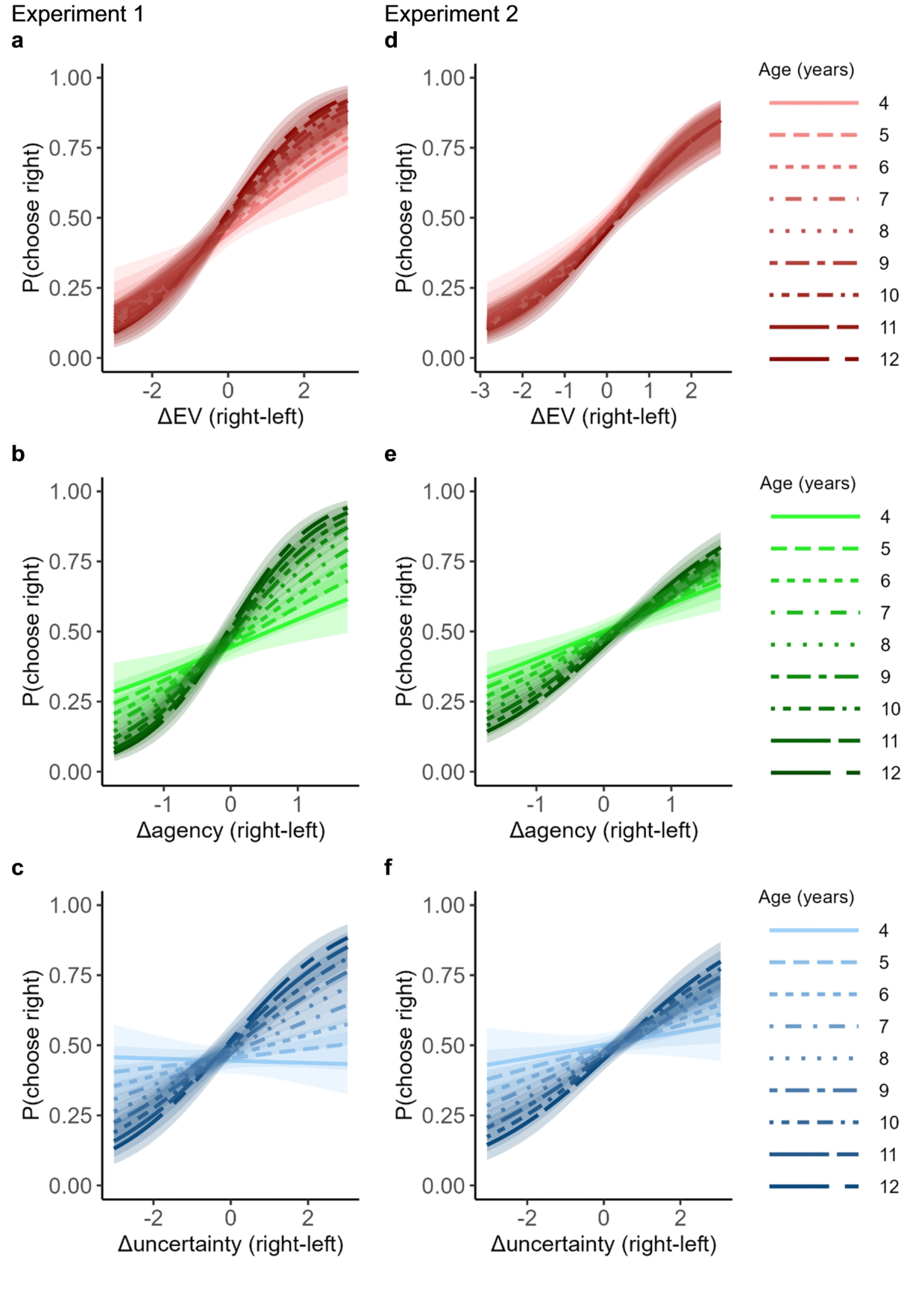 Multifaceted information-seeking motives in childrenGaia Molinaro, Irene Cogliati Dezza, Sarah Katharina Bühler, and 2 more authorsNature Communications, 2023
Multifaceted information-seeking motives in childrenGaia Molinaro, Irene Cogliati Dezza, Sarah Katharina Bühler, and 2 more authorsNature Communications, 2023From an early age, children need to gather information to learn about their environment. Deciding which knowledge to pursue can be difficult because information can serve several, sometimes competing, purposes. Here, we examine the developmental trajectories of such diverse information-seeking motives. Over five experiments involving 521 children (aged 4–12), we find that school-age children integrate three key factors into their information-seeking choices: whether information reduces uncertainty, is useful in directing action, and is likely to be positive. Choices that likely reveal positive information and are useful for action emerge as early as age 4, followed by choices that reduce uncertainty (at age 5). Our results suggest that motives related to usefulness and uncertainty reduction become stronger with age, while the tendency to seek positive news does not show a statistically significant change throughout development. This study reveals how the relative importance of diverging, sometimes conflicting, information-seeking motives emerges throughout development.
@article{molinaro2023multifaceted, title = {Multifaceted information-seeking motives in children}, author = {Molinaro, Gaia and Cogliati Dezza, Irene and B{\"u}hler, Sarah Katharina and Moutsiana, Christina and Sharot, Tali}, journal = {Nature Communications}, volume = {14}, number = {1}, pages = {5505}, year = {2023}, publisher = {Nature Publishing Group UK London}, }